Large Language Models have transformed AI applications across industries, but their generic training often falls short of specific business requirements. To bridge this gap, organizations typically turn to two primary enhancement techniques: Retrieval-Augmented Generation (RAG) and Fine-tuning. Each approach offers distinct advantages and addresses different challenges in customizing LLMs for specialized tasks.
Understanding RAG: Dynamic Knowledge Access
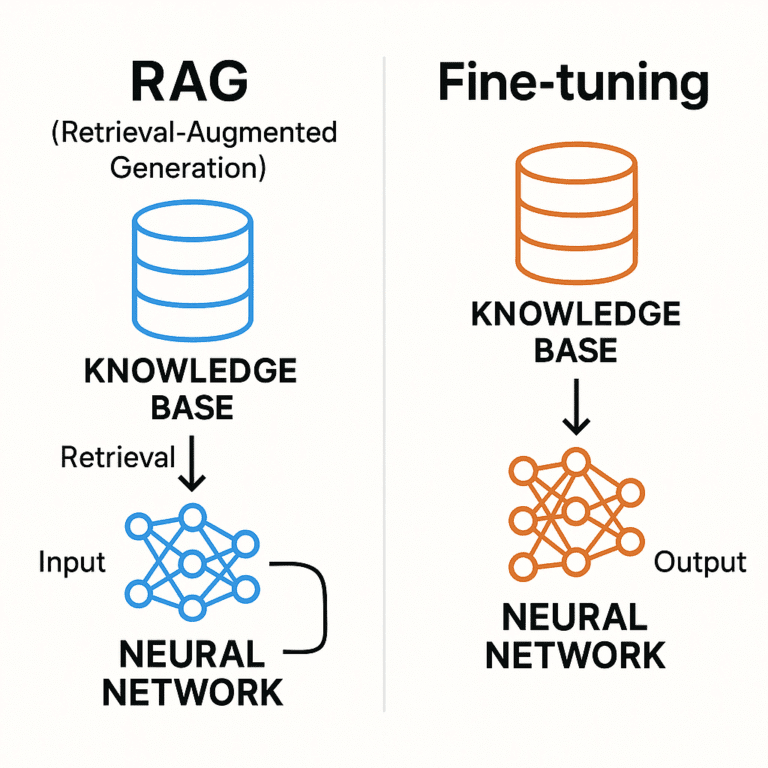
Retrieval-Augmented Generation (RAG) is a technique that enhances LLMs by connecting them to external knowledge sources during inference. Rather than relying solely on pre-trained parameters, RAG operates through a multi-step process that dynamically retrieves relevant information and incorporates it into response generation.
How RAG Works
RAG operates through four key stages:
Indexing: Data is converted into embeddings—numerical representations stored in vector databases for efficient retrieval. This process works with unstructured text, semi-structured data, or structured knowledge graphs.
Retrieval: When a user submits a query, the system searches for the most relevant documents using similarity comparisons between the query and stored embeddings.
Augmentation: Retrieved information is integrated into the original query through prompt engineering, providing the LLM with relevant context.
Generation: The LLM generates responses based on both the original query and the retrieved information.
RAG Advantages
Real-time Information Access: RAG excels at providing current, up-to-date information without requiring model retraining. Organizations can update their knowledge base and immediately see improvements in response accuracy.
Reduced Hallucinations: By grounding responses in verified external sources, RAG significantly minimizes the risk of fabricated or inaccurate information. Each response can be traced back to specific documents, enhancing transparency and reliability.
Cost-Effective Updates: RAG avoids the computational expense of retraining models when new information becomes available. Updates only require refreshing the knowledge base rather than the entire model.
Source Attribution: RAG systems can provide citations and references, allowing users to verify information and understand the basis for generated responses.
RAG Limitations
Dependency on Data Quality: RAG performance is fundamentally limited by the quality and relevance of external data sources. Poor or outdated information in the knowledge base directly impacts response accuracy.
Increased Complexity: RAG systems require managing multiple components—retrieval mechanisms, vector databases, and generation models—creating additional points of failure and maintenance overhead.
Higher Infrastructure Costs: The dual pipeline of retrieval and generation demands significant computational resources, storage for large knowledge bases, and high-performance infrastructure for real-time responses.
Limited Customization: RAG maintains the original model’s behavior and style, offering less control over response tone or domain-specific reasoning patterns.
Understanding Fine-Tuning: Deep Model Specialization
Fine-tuning is the process of adapting a pre-trained model by continuing training on smaller, task-specific datasets. This approach modifies the model’s internal parameters to better understand and generate content for specialized domains.
How Fine-Tuning Works
Fine-tuning typically follows these steps:
Model Selection: Choose a pre-trained model that aligns with your task requirements, such as BERT for NLP tasks or GPT models for text generation.
Layer Management: Freeze early layers that capture basic features while updating later layers for task-specific specialization.
Training: Use domain-specific data with carefully tuned learning rates to adjust model parameters without completely overwriting pre-trained knowledge.
Validation: Iteratively test and refine the model’s performance on target tasks.
Fine-Tuning Advantages
Deep Domain Understanding: Fine-tuning embeds specialized knowledge directly into model parameters, creating deep understanding of domain-specific terminology and concepts. This results in more nuanced and contextually appropriate responses.
Consistent Performance: Fine-tuned models deliver reliable, reproducible outputs within their specialized domain, making them ideal for applications requiring consistent behavior.
Lower Inference Costs: Once trained, fine-tuned models don’t require additional retrieval operations during inference, resulting in faster response times and lower operational costs.
Style and Tone Customization: Fine-tuning allows complete control over response style, tone, and formatting to match specific brand requirements or professional standards.
Fine-Tuning Limitations
High Initial Costs: Fine-tuning requires significant computational resources, with GPU costs ranging from $0.50 to $40+ per hour depending on model size and complexity. Total costs can range from hundreds to thousands of dollars.
Static Knowledge: Fine-tuned models are limited to information available at training time and cannot access new data without retraining. This makes them unsuitable for rapidly changing domains.
Data Requirements: Effective fine-tuning demands high-quality, labeled datasets and careful data preparation, which can be time-intensive and expensive.
Risk of Overfitting: Models may become too specialized, losing generalization capabilities or performing poorly on edge cases not covered in training data.
Cost Comparison: RAG vs Fine-Tuning
RAG Costs
RAG implementations typically involve:
- Compute Resources: $20,000+ monthly for high-performance GPU infrastructure supporting continuous operations
- Storage: ~$2,300/month for 100TB of knowledge base storage
- Infrastructure: Vector database management, embedding generation, and retrieval systems
- Ongoing Maintenance: Regular data updates and system monitoring
Fine-Tuning Costs
Fine-tuning expenses include:
- Training Infrastructure: $953-$3,200+ monthly for GPU resources during training
- Data Preparation: 300-500 person-hours for initial dataset creation and cleaning
- Training Time: $0.50-$2+ per GPU hour, potentially lasting days for large models
- One-time Investment: GPT-4o fine-tuning starts at ~$0.78 for small datasets but scales significantly
When to Choose Each Approach
Choose RAG When:
- Dynamic Information Needs: Applications requiring real-time, frequently updated data such as news, market analysis, or regulatory compliance
- Rapid Deployment: Projects needing quick implementation without extensive model training
- Transparency Requirements: Use cases where source attribution and response verification are critical
- Resource Constraints: Situations where retraining models is impractical or expensive
Ideal RAG Use Cases:
- Customer support with evolving product information
- Financial analysis requiring current market data
- Legal research accessing recent case law and regulations
- Internal knowledge bases with frequent updates
Choose Fine-Tuning When:
- Domain Expertise: Applications requiring deep understanding of specialized terminology and concepts
- Consistent Behavior: Use cases demanding reliable, predictable responses within specific domains
- Style Requirements: Applications needing specific tone, format, or brand alignment
- Stable Knowledge: Domains where information changes infrequently
Ideal Fine-Tuning Use Cases:
- Medical diagnosis systems requiring specialized medical knowledge
- Legal document analysis with domain-specific terminology
- Industry-specific content generation with consistent style
- Compliance monitoring in regulated industries
Hybrid Approaches: RAFT and Beyond
Recent research has introduced Retrieval-Augmented Fine-Tuning (RAFT), which combines both approaches to maximize their respective benefits. RAFT fine-tunes models specifically for open-book scenarios where they must effectively use retrieved documents while ignoring irrelevant information.
RAFT Methodology
RAFT trains models using datasets that include:
- Questions paired with both relevant documents and distractors
- Chain-of-thought reasoning that explains how answers derive from specific documents
- Training scenarios with varying levels of document relevance
This approach teaches models to identify useful information while disregarding irrelevant content, resulting in improved performance across domains like PubMed, HotpotQA, and technical documentation.
Implementing Hybrid Systems
Organizations can combine RAG and fine-tuning through:
Sequential Implementation: First fine-tune a model for domain expertise, then deploy it within a RAG architecture for real-time information access.
Joint Training: Simultaneously optimize both retrieval and generation components for specific domains.
Task-Specific Optimization: Use fine-tuning for consistent behavior and RAG for dynamic knowledge access within the same application.
Making the Right Choice
The decision between RAG and fine-tuning depends on several key factors:
Data Characteristics: Dynamic, frequently changing information favors RAG, while stable domain knowledge benefits from fine-tuning.
Performance Requirements: Fine-tuning provides more consistent, specialized performance, while RAG offers broader knowledge access.
Resource Availability: Consider both upfront training costs and ongoing operational expenses.
Technical Complexity: RAG requires managing multiple system components, while fine-tuning demands ML expertise and careful training processes.
Timeline Constraints: RAG enables faster deployment, while fine-tuning requires significant upfront investment in training time.
Both RAG and fine-tuning represent powerful approaches to enhancing LLM capabilities, each addressing different aspects of model customization. RAG excels in dynamic environments requiring real-time information access and source verification, while fine-tuning creates specialized models with deep domain understanding and consistent performance. The emerging hybrid approaches like RAFT suggest that the future of LLM enhancement may lie in thoughtfully combining these techniques to leverage their complementary strengths. Organizations should carefully evaluate their specific requirements, resources, and constraints to select the most appropriate approach for their unique use cases.

